效果:
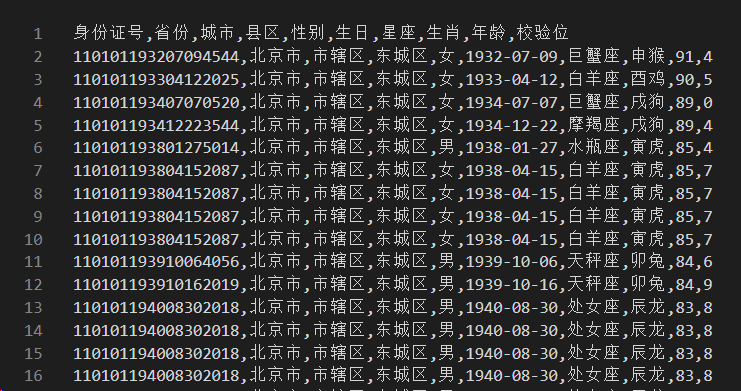
实现思路:
写的时候python有三个库,但是我发现大多数都不全,而且不到区,最后找到了id_validator,蛮不错的,实测处理一百万数据没问题。
让GPT帮我写一下思路,我懒得写
这个Python脚本用于处理包含中国身份证号的文本文件,提取省市县等信息,并生成一个CSV文件。以下是代码的实现思路和使用方法:
实现概述:
- 导入库:
re: 用于正则表达式文本匹配。csv: 用于读写CSV文件。argparse: 用于解析命令行参数。id_validator: 一个用于验证和提取中国身份证信息的外部库。ThreadPoolExecutor: 属于concurrent.futures模块,用于并行执行任务。
- 验证和信息提取:
is_valid_id_number(id_number): 使用id_validator库检查给定的身份证号是否有效。extract_id_numbers_from_text(text): 使用正则表达式从输入文本中提取18位身份证号。
- 处理身份证号:
process_id_number(id_number): 处理有效的身份证号,通过id_validator库提取省市、城市和生日等信息。
- 处理文本文件:
process_txt_file(input_file, output_csv): 读取输入文本文件,提取身份证号,并使用线程池并行处理。然后将提取的信息写入CSV文件。
- 命令行界面:
- 使用
argparse模块创建命令行界面。脚本需要两个必需参数:--file用于输入文本文件,--outfile用于输出CSV文件。
- 使用
如何使用:
- 命令行:
- 从命令行运行脚本。
- 示例:
python script_name.py --file input.txt --outfile output.csv
- 输入文件:
- 输入文件 (
input.txt) 应包含包含中国身份证号的文本。
- 输入文件 (
- 输出文件:
- 输出文件 (
output.csv) 将被生成,其中包含从身份证号中提取的信息。
- 输出文件 (
- 并行处理:
- 脚本使用线程池 (
ThreadPoolExecutor) 并行处理身份证号,提高效率。
- 脚本使用线程池 (
- 错误处理:
- 脚本处理个别身份证号处理过程中的错误,并打印详细信息。
该脚本的目标是自动从给定文本文件中提取中国身份证号的信息,提供结构化的CSV格式,包括地点、性别、生日等详细信息。
实现:
python china_idcard.py --file user_card.txt --outfile user_card.csv代码:
import re
import csv
import argparse
from id_validator import validator
from concurrent.futures import ThreadPoolExecutor
def is_valid_id_number(id_number):
return validator.is_valid(id_number)
def extract_id_numbers_from_text(text):
return re.findall(r'\b\d{18}\b', text)
def process_id_number(id_number):
if is_valid_id_number(id_number):
id_info = validator.get_info(id_number)
address_tree = id_info.get('address_tree', [])
province = address_tree[0] if address_tree else '未知'
city = address_tree[1] if len(address_tree) > 1 else '未知'
district = address_tree[2] if len(address_tree) > 2 else '未知'
print(f"处理身份证号 {id_number},信息: {id_info}")
return {
'身份证号': id_number,
'省份': province,
'城市': city,
'县区': district,
'性别': '男' if id_info.get('sex') == 1 else '女' if id_info.get('sex') == 0 else '未知',
'生日': id_info.get('birthday_code', '未知'),
'星座': id_info.get('constellation', '未知'),
'生肖': id_info.get('chinese_zodiac', '未知'),
'年龄': id_info.get('age', '未知'),
'校验位': id_info.get('check_bit', '未知')
}
return None
def process_txt_file(input_file, output_csv):
with open(input_file, 'r', encoding='utf-8') as file:
lines = file.readlines()
total_lines = len(lines)
print(f"共识别出 {total_lines} 行文本。")
results = []
with ThreadPoolExecutor() as executor:
id_numbers = [extract_id_numbers_from_text(line.strip()) for line in lines if line.strip() and len(line.strip()) >= 18]
id_numbers = [id_number for sublist in id_numbers for id_number in sublist] # Flatten the list
print_interval = 10000
for i in range(0, len(id_numbers), print_interval):
batch_ids = id_numbers[i:i+print_interval]
print(f"已处理 {i + len(batch_ids)} 行文本。")
futures = {executor.submit(process_id_number, id_number): id_number for id_number in batch_ids}
for future in futures:
id_number = futures[future]
try:
result = future.result()
if result:
results.append(result)
except Exception as e:
print(f"处理身份证号 {id_number} 时出错: {e}")
print(f"总共已处理 {len(results)} 行文本。")
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['身份证号', '省份', '城市', '县区', '性别', '生日', '星座', '生肖', '年龄', '校验位']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(results)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='处理包含中国身份证号的文本文件,并提取省市县信息生成CSV文件。')
parser.add_argument('--file', type=str, help='输入文本文件名', required=True)
parser.add_argument('--outfile', type=str, help='输出CSV文件名', required=True)
args = parser.parse_args()
process_txt_file(args.file, args.outfile)