需求:
我这里要统计一个平台的用户手机号在全国分布归属地,但是这么大数据量,使用在线接口要收费,本着能不花钱就不花钱的宗旨,使用python的库来实现
让GPT帮我介绍这段代码:
这段代码是一个用于批量识别中国手机号码归属地的脚本。以下是代码的功能和使用方法的介绍:
功能:
- 读取包含手机号码的文本文件。
- 使用
phonenumbers库解析手机号码,判断其是否有效。 - 查询有效手机号码的归属地信息,包括省和市。
- 将识别结果写入CSV文件,同时记录处理成功和失败的数量。
使用方法:
- 通过命令行参数传入包含手机号的文本文件路径
--file和输出结果文件路径--outfile。 - 使用
ThreadPoolExecutor并行处理手机号码,提高处理效率。 - 输出结果文件为CSV格式,包含手机号码、省份、城市信息。
- 错误的手机号码将记录在
error.txt文件中。
编写思路:
- 导入必要的库:
csv用于处理CSV文件,phonenumbers用于解析和查询手机号码归属地,argparse用于处理命令行参数,concurrent.futures中的ThreadPoolExecutor用于并行处理手机号码。 - 定义
query_location函数,根据手机号码查询归属地,返回手机号码和归属地信息。 - 定义
process_phone_number函数,验证手机号码格式,调用query_location函数查询归属地,记录处理成功和失败的数量。 - 定义
process_phone_numbers函数,读取包含手机号的文本文件,使用线程池并行处理手机号码,将结果写入CSV文件,并记录处理统计信息。 - 定义
extract_province_city函数,从归属地信息中提取省份和城市。 - 定义
main函数,使用argparse解析命令行参数,调用process_phone_numbers处理手机号码。 - 在
__main__块中调用main函数,执行脚本。
使用时通过命令行运行脚本,提供包含手机号的文本文件路径和输出结果文件路径。脚本会并行处理手机号码,输出CSV文件,并记录处理统计信息和错误信息。
使用方法:
python main_phone.py --file us_user_phone.txt --outfile us_user_phone.csv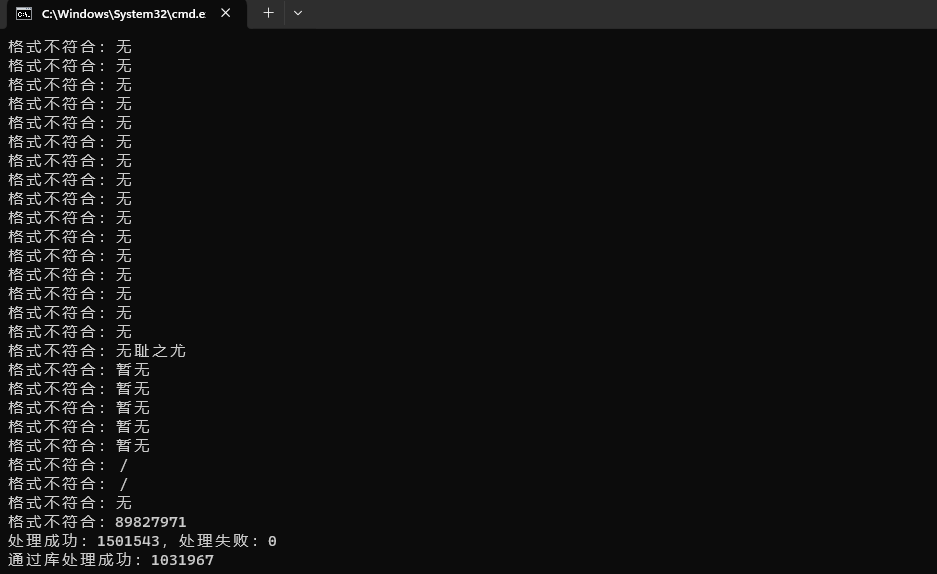
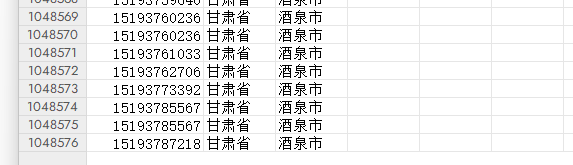
效果:
实现代码:
import csv
import phonenumbers
from phonenumbers import geocoder
import random
from concurrent.futures import ThreadPoolExecutor
import argparse
def query_location(phone_number):
try:
parsed_number = phonenumbers.parse(phone_number, 'CN')
if phonenumbers.is_valid_number(parsed_number):
region = geocoder.description_for_number(parsed_number, 'zh')
return f"{phone_number},{region}", 'library'
else:
return None, None
except phonenumbers.NumberFormatException:
return None, None
def process_phone_number(phone_number):
if not phone_number.isdigit() or len(phone_number) != 11 or not phone_number.startswith('1'):
print(f"格式不符合:{phone_number}")
return f"{phone_number},格式不符合", None
result, source = query_location(phone_number)
if result:
return result, source
else:
print(f"{phone_number} 不是有效的手机号码,跳过...")
return f"{phone_number},查询失败", None
def process_phone_numbers(file_path, outfile_path):
success_count = 0
failure_count = 0
library_count = 0
success_results = []
failure_results = []
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(process_phone_number, line.strip()) for line in lines]
for future in futures:
result, source = future.result()
if result:
success_count += 1
success_results.append(result)
if source == 'library':
library_count += 1
else:
failure_count += 1
failure_results.append(result)
print(f"处理成功:{success_count},处理失败:{failure_count}")
print(f"通过库处理成功:{library_count}")
with open(outfile_path, 'w', newline='', encoding='utf-8') as out_file:
out_writer = csv.writer(out_file)
out_writer.writerow(['手机号码', '省', '市'])
for result in success_results:
# 检查结果是否包含省和市信息
if ',' in result:
parts = result.split(',')
phone = parts[0]
location = parts[1]
province, city = extract_province_city(location)
out_writer.writerow([phone, province, city])
else:
phone, _ = result.split(',')
out_writer.writerow([phone, '未知', '未知'])
with open('error.txt', 'w', encoding='utf-8') as error_file:
error_file.write('\n'.join(failure_results))
def extract_province_city(location):
parts = location.split('省')
if len(parts) > 1:
province = parts[0] + '省'
city = parts[1]
else:
province = location
city = '未知'
return province, city
def main():
parser = argparse.ArgumentParser(description='批量识别手机号归属地并统计')
parser.add_argument('--file', help='包含手机号的文本文件路径')
parser.add_argument('--outfile', help='输出结果文件路径')
args = parser.parse_args()
if args.file and args.outfile:
process_phone_numbers(args.file, args.outfile)
else:
print("请提供包含手机号的文本文件路径和输出结果文件路径,使用 --file 和 --outfile 参数。")
if __name__ == "__main__":
main()